cuernylabs.ai

Build and Evolve Systems at the Speed of AI.

When Building Is the Practical Choice
Off-the-shelf platforms can accelerate early delivery, but they often introduce hidden constraints that surface later as cost, rigidity, or operational complexity.Many teams default to buying because building feels slow or risky. In practice, that assumption often breaks down once real workflows, data models, and edge cases are introduced.We build custom systems when existing platforms become the bottleneck rather than the accelerator, especially when:
Core logic can’t be expressed cleanly through configuration
Integration overhead dominates delivery time
Data ownership or observability becomes critical
Long-term change velocity matters more than short-term setup
In those cases, a focused build is often the fastest path to a system that actually fits the business.

How We Design for real Constraints
We approach system design by starting from how the system actually operates today, the data that exists, the workflows people use, and the operational realities it will face in production.Most systems don’t fail because of a bad high-level choice. They fail because constraints are misunderstood or deferred until they’re expensive to fix.Rather than designing in the abstract, we focus on where systems tend to break down over time:
What can ship quickly versus what becomes hard to change later
Where configuration stops being sufficient and code must take over
How tightly the system is coupled to vendors and external platforms
Whether the team controls the data and can observe behavior in production
How cost, reliability, and operational load evolve as usage grows

Design the Right System. Then Build It.
A short, hands-on engagement where we work through your system and constraints to produce a build-ready design.
You’ll speak directly with an engineer. No sales team. No pressure.
Evolve Existing Systems Without Breaking Them
Most existing systems encode years of business logic, edge cases, and operational knowledge. Replacing them outright is rarely necessary and often introduces avoidable risk.We take an incremental approach to system evolution. That means isolating critical paths, understanding where complexity actually lives, and rebuilding high-leverage components in a way that coexists cleanly with what’s already running.In practice, this looks like:
Identifying the parts of the system that limit change or throughput
Extracting or rebuilding those components behind stable interfaces
Introducing new services or workflows without disrupting existing users
Letting old and new systems run side by side until confidence is earned
The result is steady forward progress without the downtime, cost, or failure modes associated with full rewrites.
A 30-minute deep dive with a technical expert. No sales pitch, just a path forward.

Our System of Work
We operate as a small, senior-only team with a deliberately designed system of work that prioritizes throughput, correctness, and adaptability under real constraints.Rather than scaling through headcount, we scale through leverage. We rely on automation, AI-assisted workflows, and shared internal tooling to compress feedback loops, reduce coordination overhead, and keep decisions close to implementation.Elite Efficiency — A small, senior team minimizes handoffs, communication overhead, and shipping delays by keeping design and execution tightly coupled.
Rapid Prototyping — We use focused prototypes and production-grade spikes to validate architecture, data flow, and feasibility early, then carry successful designs forward into production.
AI-Augmented Delivery — We use AI-assisted workflows across design exploration, implementation, and review to increase throughput and iteration speed without sacrificing correctness or maintainability.
Founder-Led Development — Systems are designed and built directly by senior engineers with experience delivering complex platforms in large-scale production environments.

© Untitled. All rights reserved.

Founders

Benjamin Peters | Founder & CTO
Benjamin is a software engineer with over a decade of experience building and evolving mission-critical systems at companies including Atlassian, Visa, Secureworks, Anaconda, and Oracle.A Carnegie Mellon alumnus with a Master’s in Information Systems Management, his work spans backend platforms, big data and distributed systems, and AI infrastructure and platforms, with a focus on building production-grade software under real constraints.He founded CuernyLabs to apply the same engineering rigor used in large-scale environments to smaller teams that need custom systems built quickly, correctly, and without unnecessary complexity.

Chenyuan Zhang | Cofounder & Principal Architect
Chenyuan is a software architect with over a decade of experience designing and building high-scale, data-intensive systems at companies including Indeed, WorldQuant, and Anaconda.A Carnegie Mellon MISM alumna, her work includes building AI- and LLM-powered recommendation systems for job search, as well as dependency-driven DAG scheduling systems for large-scale trading alpha workloads and high-throughput event-driven platforms.At CuernyLabs, she applies this background in AI-driven systems and orchestration to design and build lean, production-grade systems that solve complex business logic without unnecessary operational overhead.

Technical Briefs
The examples below reflect systems designed and built by our founders in prior roles and represent the types of engagements we take on.

Let’s Architect Your Next Move
Whether you're deconstructing a legacy monolith or building a new AI-native platform, we’re here to help you move faster. Drop us a note about your technical hurdles, and let's see if we’re the right fit to solve them.
Currently accepting a small number of advisory or build engagements

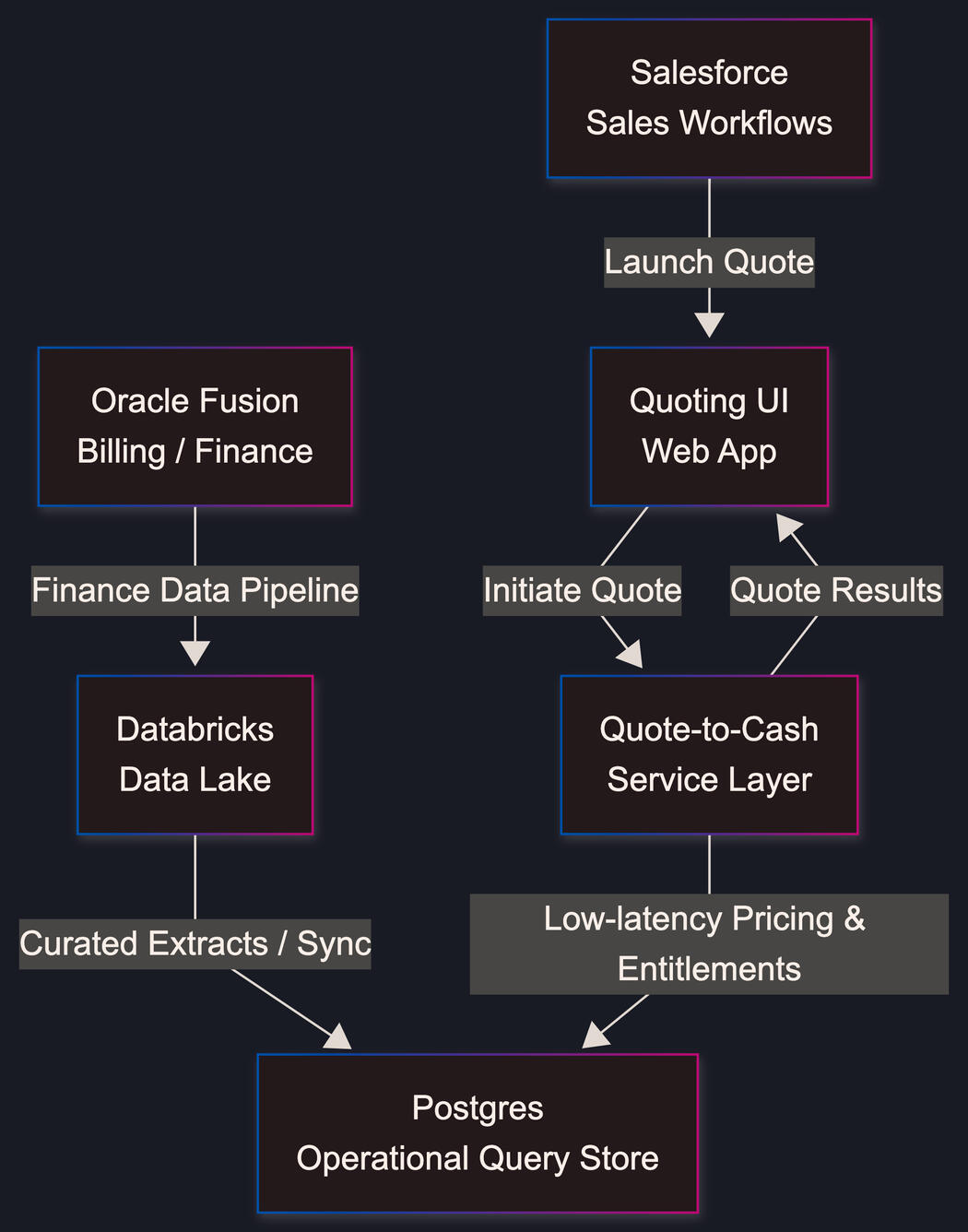
Quote-to-Cash Platform (Build vs Buy)A large enterprise sales organization needed a production-ready Quote-to-Cash (Q2C) system that allowed sales teams to generate accurate customer quotes directly from existing workflows.Commercial Q2C platforms were considered, but the problem space was constrained by:Non-trivial pricing and entitlement logicDeep integration requirements across existing enterprise systemsA fixed delivery window of one quarter to ship a usable v1The requirement was explicit:
make the build vs buy decision and deliver a working system within 90 days.The ChallengeThe core challenge was not building a quoting UI — it was coordinating data and logic across multiple enterprise systems without introducing duplication or inconsistency.At the outset:
- Sales workflows lived in Salesforce
- Pricing, entitlements, and billing logic originated in Oracle Fusion
- Curated finance and operational data already existed in a Databricks data lakeOff-the-shelf Q2C platforms introduced several risks relative to the delivery window:
- Long implementation and configuration timelines
- Limited flexibility for the organization’s pricing and approval rules
- Significant integration overhead for data that already existed elsewhereBuying carried the risk of missing the quarter due to implementation lead time.
Building carried the risk of scope creep and production readiness if not tightly controlled.The DecisionWe ran a focused Build vs Buy assessment grounded in the constraints of the quarter, not in feature comparisons.The evaluation centered on:
- Whether value could be delivered within a fixed 90-day window
- How much existing enterprise data could be reused directly
- Control over pricing and quoting logic
- The ability to extend the system safely after v1A key input was the organization’s existing Databricks data lake, which already contained curated billing and finance data sourced from Oracle Fusion.That foundation eliminated the need to re-implement large portions of a commercial Q2C platform. Instead of adopting a full product, the decision was to build a narrowly scoped, production-grade system that focused on orchestration and quoting logic while reusing existing sources of truth.The ApproachRather than attempting a full end-to-end replacement, the system was designed as a thin orchestration layer:- Salesforce remained the system of engagement for sales
- Databricks served as the authoritative source for pricing and billing data
- Oracle Fusion continued to own billing and financial truth
- The new service layer focused exclusively on:
- Quote generation
- Pricing composition
- Validation and approvalsThis approach allowed the team to:
- Reuse trusted enterprise data
- Avoid duplicating financial logic
- Deliver quickly without architectural shortcutsThe OutcomeWithin a single quarter, the team delivered:
- A production-ready v1 Quote-to-Cash system
- Seamless Salesforce-initiated quote creation
- Accurate pricing driven by existing billing data
- A clean architectural foundation for future expansionOperationally, the system:
- Met the delivery deadline
- Avoided vendor lock-in
- Scaled naturally as additional requirements were introducedMost importantly, it replaced a slow, manual quoting process with an automated workflow that reduced quote turnaround time from days, and in some cases weeks, to minutes for standard quotes.Why This MattersThis engagement illustrates that Build vs Buy is not a philosophical decision, it's a constraint-driven one.By grounding the approach in:
- A fixed delivery window
- Existing enterprise data investments
- Real operational workflowsThe team delivered a system that:
- Fit actual sales and billing processes
- Leveraged existing data instead of duplicating it
- Remained adaptable beyond the initial releaseThe result was not just a successful v1, but a platform that could evolve incrementally without forcing the organization into a generic Q2C solution that didn’t match its reality.

Anomaly Detection System (Financial Data)
A finance organization needed a way to identify anomalous financial activity across large volumes of transactional data without relying on static rules or manual review.The goal was not to deploy a fully productionized ML platform immediately, but to prove feasibility:
could a model-driven approach surface meaningful anomalies using existing data — and integrate cleanly into existing systems and workflows?The engagement was scoped as a proof of concept, delivered over a few weeks, with a focus on correctness, extensibility, and operational fit.The Challenge
The organization already had large volumes of financial data available in a Databricks data lake, but anomaly detection was largely manual and reactive.Key constraints included:
- High data volume with evolving distributions
- Limited labeled data for supervised learning
- The need to integrate with an existing Java-based microservice architecture
- A requirement for human review and feedback before acting on anomaliesThe system needed to:
- Support multiple detection approaches
- Run on a schedule without manual intervention
- Surface actionable alerts, not just statistical outliers
- Allow analyst feedback to improve accuracy over timeThe Approach
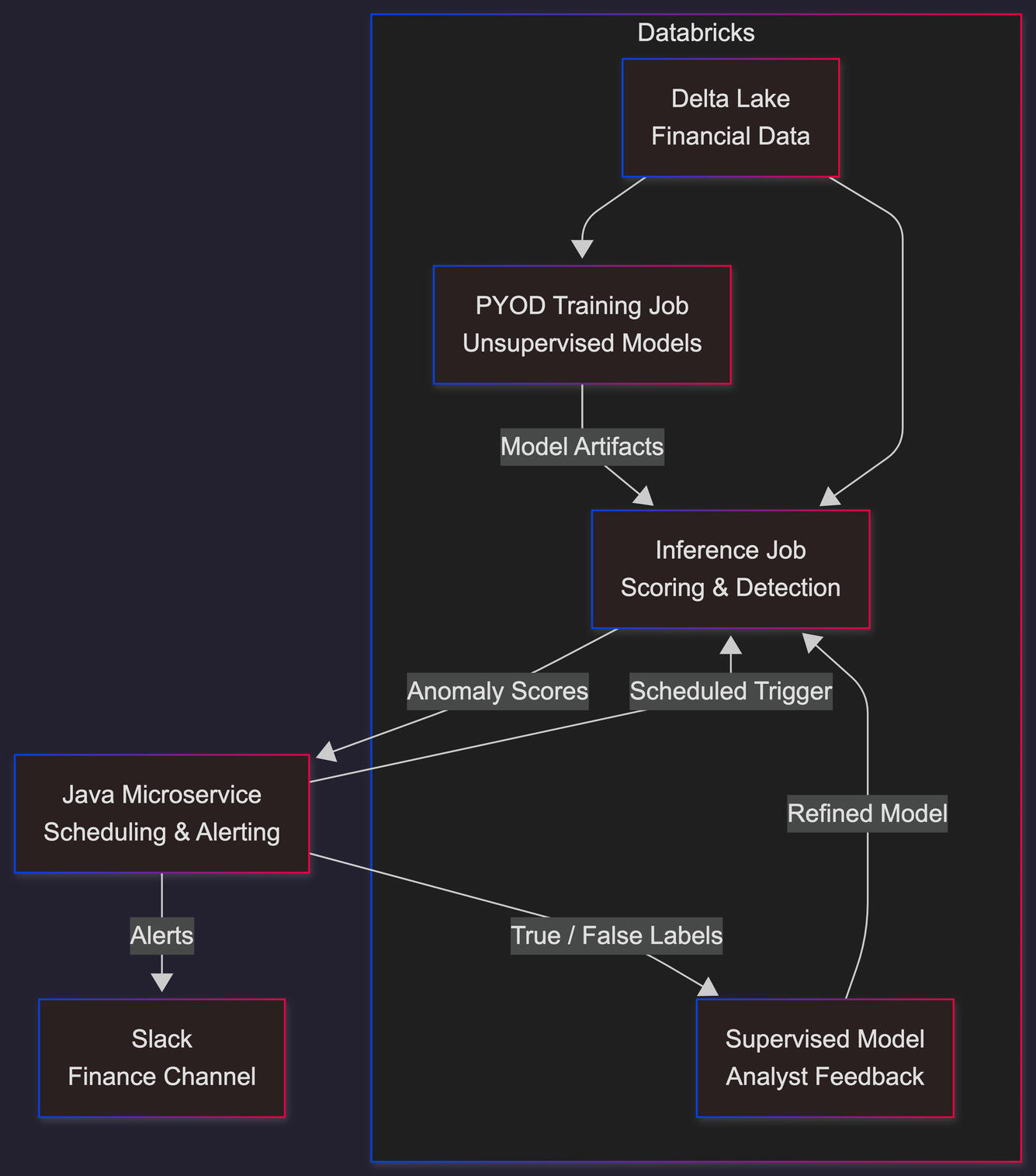
The POC was designed to maximize reuse of existing infrastructure while keeping the detection logic modular and extensible.Model StrategyRather than committing to a single algorithm, the system used PYOD (Python Outlier Detection) as a unified interface over multiple unsupervised anomaly detection models.This allowed:
- Rapid experimentation across different detection techniques
- Consistent training and inference workflows
- Model selection without rewriting pipeline logicTraining and Scheduling
- Training jobs were implemented in Databricks and scheduled to run automatically
- Models were retrained on a cadence to account for changing data distributions
- Training artifacts were versioned to support comparison and rollbackInference and IntegrationA configurable inference job was exposed that could be invoked by an existing Java microservice.In practice:
- The Java service triggered and collected inference results
- The inference job scored the data using the active model configuration
- Potential anomalies were identified and scored
- Alerts were generated and routed to finance team members for reviewThis design kept the ML logic decoupled from the core application while still allowing real-time or near–real-time evaluation.Feedback Loop and Hybrid Detection
A critical requirement was the ability for analysts to validate anomalies rather than blindly act on them.The system supported:
- Analyst review of flagged anomalies
- Explicit marking of true positives and false positives
- Storage of labeled outcomes for future useThese labels enabled a hybrid detection approach:
- Unsupervised models continued to surface novel or unexpected patterns
- Supervised models were trained incrementally using analyst feedbackOver time, the system improved precision while retaining the ability to detect new classes of anomaliesThis avoided the common failure mode of purely unsupervised systems (high noise) and purely supervised systems (blindness to new patterns).The OutcomeWithin a few weeks, the POC delivered:
- A working anomaly detection pipeline operating on real financial data
- Automated model training and scheduled execution in Databricks
- A configurable inference path callable from existing services
- Analyst-facing alerts with a built-in feedback mechanismThe system demonstrated that:
- Existing data assets were sufficient to support model-driven detection
- Anomalies of interest could be surfaced without hand-written rules
- Analyst feedback could be incorporated to improve accuracy over timeMost importantly, the POC validated an approach that could be incrementally productionized rather than replaced.Why This MattersThis case study highlights a pragmatic approach to ML systems:
- Start with existing data and infrastructure
- Treat models as components, not the system
- Keep humans in the loop
- Design for iteration, not perfectionRather than over-investing in a monolithic ML platform, the organization was able to validate anomaly detection quickly, integrate it into existing workflows, and establish a clear path toward a production-grade hybrid detection system.Engineering TakeawayThe success of the POC was driven less by model choice and more by:
- Clean system boundaries
- Operational integration
- Feedback-aware design
- Constraint-driven scopeThose same principles allowed a small team to deliver meaningful results quickly without compromising future flexibility.

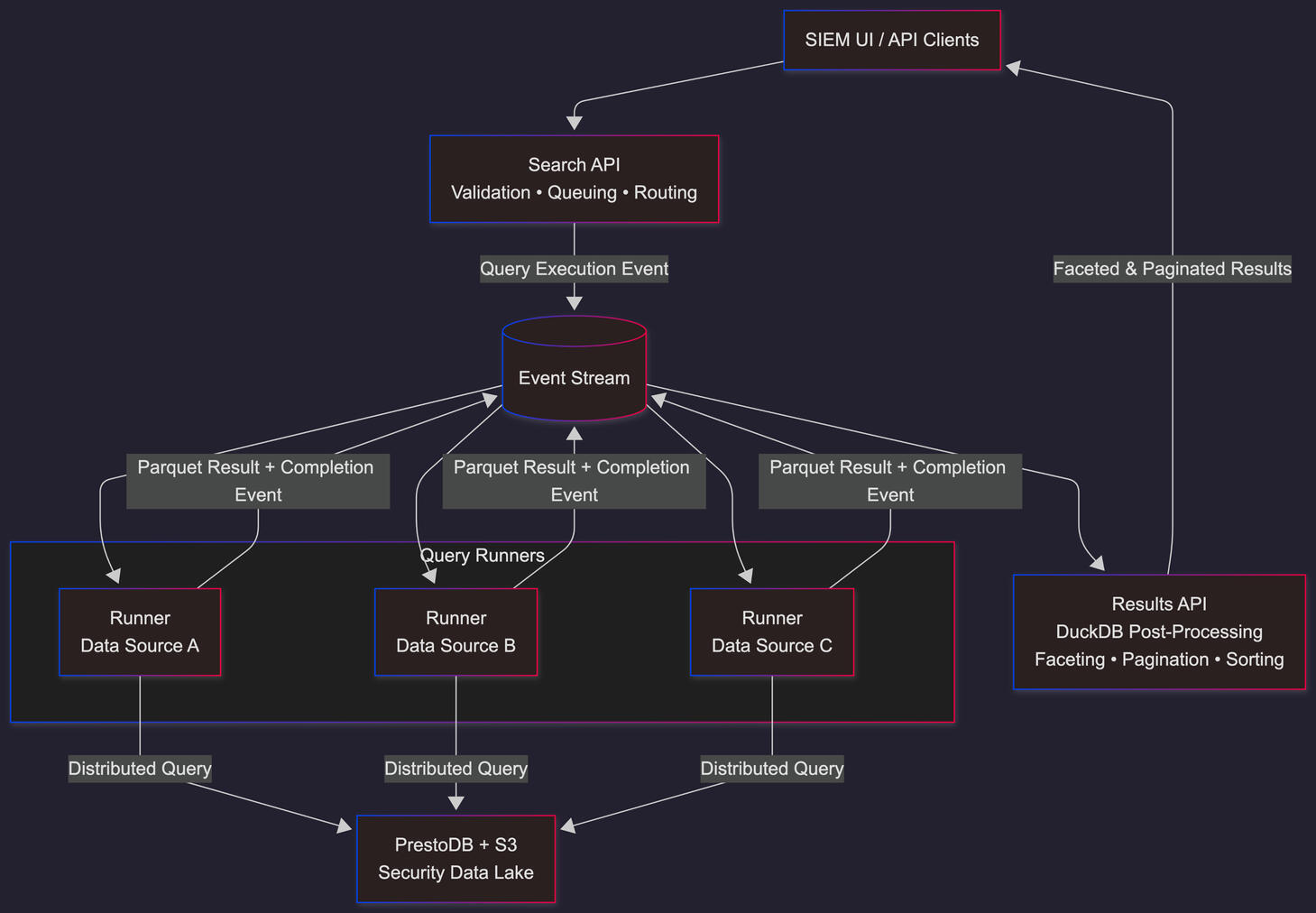
Next-Generation SIEM SearchA legacy SIEM search subsystem had become a limiting factor for both scalability and feature delivery as data volume and customer expectations increased.The system relied on a monolithic search service responsible for query execution, aggregation, and result shaping. This architecture introduced performance bottlenecks and prevented the team from delivering features customers were actively requesting, such as advanced aggregations, faceting, and reliable pagination.The underlying security data already lived in a PrestoDB / S3 data lake, and preserving that investment was a hard constraint.The ChallengeThe primary issue was not data availability, but architectural coupling.Specifically:
- Query execution and result processing were tightly bound
- Aggregation-heavy workloads degraded search performance
- Adding new query semantics required invasive changes to shared code pathsScaling increased operational risk rather than flexibilityThe system needed to:
- Support richer query semantics without rewriting the SIEM
- Preserve existing data infrastructure and business logic
- Scale execution and result processing independently
- Avoid introducing new bottlenecks under loadThe ApproachRather than replacing the system wholesale, the search stack was redesigned as an event-driven pipeline with clear separation of responsibilities.The monolith was decomposed into three core components:Search API
Acts as the entry point for search requests.
Handles request validation, query queuing, and routing by emitting query execution events rather than executing queries synchronously.Query Runners
Independent execution services, one per data source.
Each runner subscribes to query events, executes distributed queries against the existing data sources, and emits results as Parquet artifacts.Results API
Consumes result events and performs post-processing using DuckDB, including:
- Advanced aggregations
- Faceting across large result sets
- Stable pagination and sortingDuckDB was introduced strictly as a local analytical engine for result processing, not as a primary data store.Why Event-DrivenAn event-driven flow allowed the system to:
- Prevent long-running queries from blocking request handling
- Scale execution and result processing independently
- Introduce new runners or processors without rewiring the systemThis shifted the architecture from synchronous coordination to asynchronous composition.The OutcomeThe redesigned search stack:
- Removed scaling bottlenecks caused by monolithic result processing
- Unblocked advanced aggregations, faceting, and reliable pagination
- Preserved existing data infrastructure and operational knowledge
- Reduced migration risk by reusing proven business logic
- Customer-requested search capabilities were delivered without destabilizing the broader SIEM platform.Why This MattersThis project demonstrates that many scalability and feature limitations stem from where computation happens, not from the underlying data systems.By decoupling query orchestration, execution, and result processing — and introducing an event-driven flow — the team was able to unlock new capabilities without forcing a full rewrite or data migration.Engineering TakeawayThe effectiveness of the redesign came from:
- Clear separation of responsibilities
- Event-driven composition
- Deliberate placement of computation
- Reuse of existing data and business logicThose choices allowed the system to evolve incrementally while remaining predictable under load.